Kamis, 21 Mei 2020
Pada latihan kali ini kita akan menggunakan data dari Kaggle yaitu data pengunjung sebuah mall fiktif. Dataset bisa kamu dapatkan pada tautan berikut. Setelah data kamu unduh, buka Google Colab dan masukkan dataset ke dalam environment Colab.
Pada cell pertama kita impor library yang dibutuhkan.
- import pandas as pd
- import matplotlib.pyplot as plt
- %matplotlib inline
- import seaborn as sns
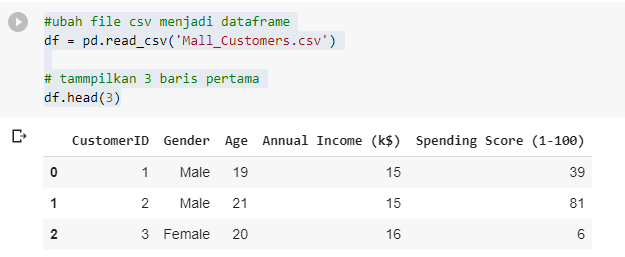
Di cell selanjutnya kita ubah file csv kita ke dalam dataframe pandas dan menampilkan 3 baris pertama dari dataframe. Pastikan file csv Anda sudah dimasukkan ke dalam Colabs.
- #ubah file csv menjadi dataframe
- df = pd.read_csv('Mall_Customers.csv')
- # tammpilkan 3 baris pertama
- df.head(3)
Tampilan dari 3 baris pertama dataframe di atas seperti berikut.
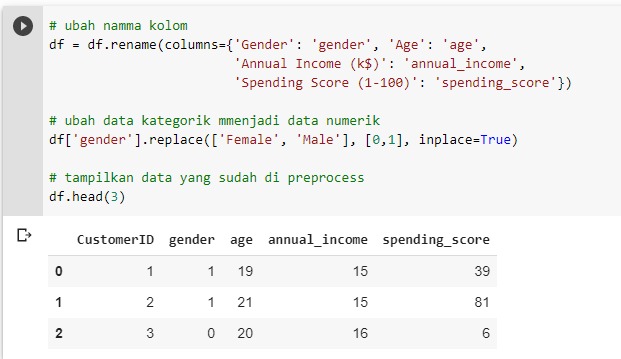
Kemudian kita akan melakukan sedikit preprocessing yaitu mengubah nama kolom agar lebih seragam. Lalu kolom gender adalah kolom kategorik, maka kita akan mengubah data tersebut menjadi data numerik.
- # ubah namma kolom
- df = df.rename(columns={'Gender': 'gender', 'Age': 'age',
- 'Annual Income (k$)': 'annual_income',
- 'Spending Score (1-100)': 'spending_score'})
- # ubah data kategorik mmenjadi data numerik
- df['gender'].replace(['Female', 'Male'], [0,1], inplace=True)
- # tampilkan data yang sudah di preprocess
- df.head(3)
Setelah dilakukan preprocessing dengan mengubah nama kolom supaya lebih seragam, maka hasilnya seperti di bawah ini.
Di tahap selanjutnya kita akan mengimpor K-Means. Di tahap ini juga kita akan menghilangkan kolom Customer ID dan gender karena kurang relevan untuk proses clustering. Selanjutnya kita akan menentukan nilai K yang optimal dengan metode Elbow. Library K-means dari SKLearn menyediakan fungsi untuk menghitung inersia dari K-Means dengan jumlah K tertentu. Di sini kita akan membuat list yang berisi inersia dari nilai K antara 1 sampai 11.
- from sklearn.cluster import KMeans
- # menghilangkan kolom customer id dan gender
- X = df.drop(['CustomerID', 'gender'], axis=1)
- #membuat list yang berisi inertia
- clusters = []
- for i in range(1,11):
- km = KMeans(n_clusters=i).fit(X)
- clusters.append(km.inertia_)
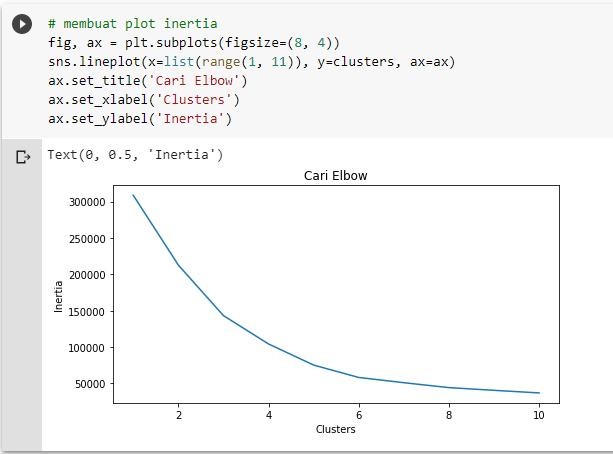
Jalankan kode di bawah untuk membuat plot dari inersia setiap K berbeda. Sesuai plot di bawah, kita bisa melihat bahwa elbow berada di nilai K sama dengan 5, di mana penurunan inersia tidak lagi signifikan setelah nilai K sama dengan 5.
- # membuat plot inertia
- fig, ax = plt.subplots(figsize=(8, 4))
- sns.lineplot(x=list(range(1, 11)), y=clusters, ax=ax)
- ax.set_title('Cari Elbow')
- ax.set_xlabel('Clusters')
- ax.set_ylabel('Inertia')
Hasil dari kode di atas menampilkan plot inersia sebagai berikut.
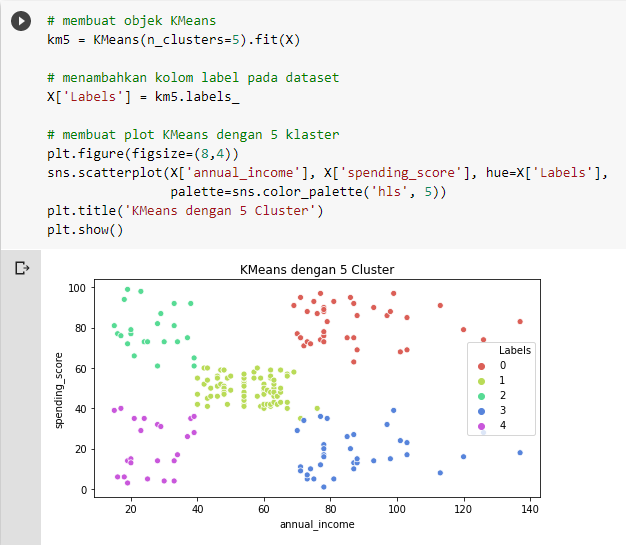
Terakhir kita bisa melatih kembali K-Means dengan jumlah K yang didapat dari metode Elbow. Lalu kita bisa membuat plot hasil pengklasteran K-Means dengan menjalankan kode di bawah.
- # membuat objek KMeans
- km5 = KMeans(n_clusters=5).fit(X)
- # menambahkan kolom label pada dataset
- X['Labels'] = km5.labels_
- # membuat plot KMeans dengan 5 klaster
- plt.figure(figsize=(8,4))
- sns.scatterplot(X['annual_income'], X['spending_score'], hue=X['Labels'],
- palette=sns.color_palette('hls', 5))
- plt.title('KMeans dengan 5 Cluster')
- plt.show()
Sehingga jika kode di atas dijalankan, maka tampilan KMeans dengan 5 klaster seperti di bawah ini.