
Kamis, 21 Mei 2020
Kode program yang akan diajarkan di sini bisa diunduh di tautan berikut ini, untuk membukanya upload berkasnya dari Google Colab.

Sekarang saatnya kita mencoba menggunakan model SVM yang tersedia di library SKLearn. Untuk latihan kali ini kita akan memakai dataset Pima Indian. Dataset ini dikumpulkan oleh National Institute of Diabetes and Digestive and Kidney Diseases.
Dataset berisi 8 kolom atribut dan 1 kolom label yang berisi 2 kelas yaitu 1 dan 0. Angka 1 menandakan bahwa orang tersebut positif diabetes dan 0 menandakan sebaliknya. Terdapat 768 sampel yang merupakan 768 pasien perempuan keturunan suku Indian Pima.
Model machine learning yang akan kita buat bertujuan untuk mengklasifikasikan apakah seorang pasien positif diabetes atau tidak.
Tahap pertama yang perlu kita lakukan adalah mengunduh dataset Pima Indian dari tautan berikut. Setelah mengunduh dataset, jangan lupa masukkan ke dalam Colab. Dataset yang telah berhasil diunggah ke Colab akan tampil sebagai berikut.
Pada tahap selanjutnya kita akan mengimpor library pandas dan mengubah dataset menjadi sebuah dataframe.
- import pandas as pd
- df = pd.read_csv('diabetes.csv')
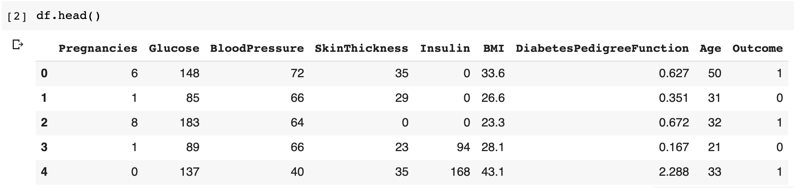
Lalu kita tampilkan 5 baris teratas dari dataframe untuk melihat isi dari dataset. Untuk melakukannya kita dapat menjalankan kode df.head() seperti di bawah.
- df.head()
Hal paling penting selanjutnya adalah kita perlu mengecek apakah terdapat nilai-nilai yang hilang pada dataset serta apakah ada atribut yang bukan berisi bilangan numerik. Kita bisa melakukan ini dengan memanggil fungsi .info() pada dataframe.
- df.info()

Output dari fungsi info() menunjukkan bahwa semua atribut nilainya lengkap, dan juga nilai-nilai dari tiap kolom memiliki tipe data numerik yaitu int64 dan float64.
Pada tahap ini data sudah bisa dipakai untuk pelatihan model.
Kita lalu memisahkan antara atribut dan label pada dataframe. Untuk memisahkan kolom-kolom pada dataframe kamu bisa melihat dokumentasinya pada tautan ini.
- # memisahkan atribut pada dataset dan menyimpannya pada sebuah variabel
- X = df[df.columns[:8]]
- # memisahkan label pada dataset dan menyimpannya pada sebuah variabel
- y = df['Outcome']
Jika kita lihat, nilai-nilai pada dataset memiliki skala yang berbeda. Contohnya pada kolom Glucose dan kolom Diabetes Pedigree Function. Kita perlu mengubah nilai-nilai dari setiap atribut berada pada skala yang sama. Kita dapat mencoba menggunakan standarisasi dengan fungsi StandardScaler() dari SKLearn.
- from sklearn.preprocessing import StandardScaler
- # standarisasi nilai-nilai dari dataset
- scaler = StandardScaler()
- scaler.fit(X)
- X = scaler.transform(X)
Setelah atribut dan label dipisah, kita bisa memisahkan data untuk training dan testing menggunakan fungsi .train_test_split().
- from sklearn.model_selection import train_test_split
- X_train, X_test, y_train, y_test = train_test_split(
- X, y, test_size=0.33, random_state=42)
Kita kemudian membuat objek Support Vector Classifier dan menampungnya pada variabel clf. Akhirnya kita sampai pada tahapan yang kita tunggu-tunggu, kita memanggil fungsi fit untuk melatih model.
- from sklearn.svm import SVC
- clf = SVC()
- clf.fit(X_train, y_train)
Terakhir, kita bisa melihat bagaimana akurasi prediksi dari model yang kita latih terhadap data testing.
- clf.score(X_test, y_test)
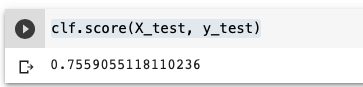
Selamat, Anda telah berhasil mengembangkan sebuah model Support Vector Classifier untuk mendeteksi diabetes
